动态内存
我们的程序到目前为止只使用过静态内存或栈内存。静态内存用来保存局部static对象(就是局部对象加上static)、类static数据成员以及定义在任何函数之外的变量。栈内存用来保存定义在函数内的非static对象。分配在静态或栈内存中的对象由编译器自动创建和销毁。对于栈对象,在其定义的程序块运行时才存在: static 对象在使用之前分配,在程序结束时销毁。
除了静态内存和栈内存,每个程序还拥有一个内存池。这部分内存被称作自由空间( free store)或堆(heap)。程序用堆来存储动态分配(dynamically allocate)的对象一即,那些在程序运行时分配的对象。动态对象的生存期由程序来控制,也就是说,当动态对象不再使用时,我们的代码必须显式地销毁它们。
动态内存与智能指针
在C++中,动态内存的管理是通过一对运算符来完成的: new,在动态内存中为对象分配空间并返回一个指向该对象的指针,我们可以选择对对象进行初始化; delete, 接受一个动态对象的指针,销毁该对象,并释放与之关联的内存。
新标准提供了两个智能指针类型类管理动态对象。他们行为类似常规指针,却可以自动的释放锁指向的对象,这两种指针的区别在于管理底层指针的方式:
shared_ ptr允许多个指针指向同-一个对象; unique_ ptr则“独占”所指向的对象。标准库还定义了一个名为weak_ ptr的伴随类,它是一种弱引用,指向shared_ ptr所管理的对象。这三种类型都定义在memory头文件中。
shared_ptr类
创建时我们也需要提供指向的类型:
1 | shared_ptr<string> p1; // shared_ _ptr, 可以指向string |
默认初始化的指针中保存着一个空指针,
智能之后着呢使用方式与普通指针类似,解引用返回指向的对象,在if使用,是检测它是否为空:
1 | //如果p1不为空,检查它是否指向一个空string |


make_shared函数
他是最安全的分配和使用动态内存的方法,函数在动态内存中分配一个对象并初始化它,返回指向此对象的shared_ptr,一样要给出创建对象类型:
1 | //指向一个值为42的int的shared_ ptr |
通常使用auto来指向它
1 | // p6指向一个动态分配的空vector<string> |
shared_ptr拷贝和赋值
1 | auto p = make shared<int>(42); // p指向的对象只有p一个引用者 |
每一个shared_ptr都会有一个关联的计数器,为引用计数。拷贝一个shared_ptr、作为参数传递给函数或者作为返回值就会递增,给shared_ptr赋予新值或者它被销毁计数器会递减。
1 | auto r = make_shared<int>(42); // r指向的int只有一个引用者 |
shared_ptr销毁管理对象
当指向一个对象的最后一个智能指针被销毁,指针的析构函数会递减指向对象的析构函数的引用计数,计数为0,指针的析构函数会销毁对象,释放内存。
且动态对象不再被使用时,shared_ptr类会自动的释放对象,特性使得动态内存的使用变得容易,例如在函数创建智能指针在离开作用域后会自动的释放掉
1 | // factory 返回一个shared_ ptr, 指向一个动态分配的对象 |
使用了动态生存期的资源的类
程序使用动态内存出于以下三种原因之一:
- 程序不知道自己需要使用多少对象
- 程序不知道所需对象的准确类型
- 程序需要在多个对象间共享数据
目前使用的类分配资源都与对应对象生存期一致。例如每个vector拥有自己的元素,当拷贝一个vector时,原vector和副本vector是相互分离的。
如果我们希望有一个类,当它进行拷贝时,不是拷贝其中成员,而是不同对象之间共享相同的元素。所以当两个对象共享底层数据,当其中一个被销毁,我们不能单方面的销毁底层数据:
1 | Blob<string> bl; // 空Blob |
定义StrBlob
这里想要实现一个StrBlob类管理string元素,如果我们在类内直接使用一个vector来保存元素,那么当多个对象中的一个被销毁时就会把底层vector销毁,所以这里使用vector保存在动态内存中。
为了实现数据共享,我们为StrBlob设置一个shared_ptr来管理动态内存分配的vector。该指针可以记录有多少个StrBlob共享相同的vector。
还需要提供一些操作,当访问一个不存在的元素,会抛出异常,且有一个默认构造和单一构造:
1 | class StrB1ob { |
StrBlob构造函数
1 | StrBlob::StrB1ob (): data (make_shared<vector<string>>()) { } |
元素访问成员函数
由于操作访问函数需要先检查存不存在,所以定义一个私有的工具函数check:
1 | void StrBlob::check(size_type i, const string &msg) const |
其他操作首先调用check,如成功则继续下一步:
1 | string& StrBlob::front () |
最后还应对front和back的const版本进行重载:
1 | const string& StrBlob::front () |
StrBlob的拷贝、赋值和销毁
该类型对象被拷贝’赋值或者销毁时,执行相应操作的是shared_ptr成员而不是vector,直到最后一个指向vector的指针对象被销毁。
直接管理内存
还可以使用new和delete来分配内存,但非常容出错。
使用new动态分配内存和初始化对象
new分配的内存是无名的,返回一个指向该对象的指针:
1 | int *pi = new int; // pi指向一个动态分配的、未初始化的无名对象 |
也可以使用列表初始化,或值初始化:
1 | int *pi = new int(1024); // pi指向的对象的值为1024 |
建议对动态分配的对象进行初始化操作。
如果提供了一个括号包围的初始化器,可以使用auto自动接管动态内存,但括号内必须仅有单一初始化器才可以使用:
1 | auto p1 = new auto (obj) ; // p指向一个与obj类型相同的对象 |
动态分配const对象
一个动态内存的const对象必须进行初始化,对于一个定义了默认构造函数的类类型,其const动态对象可以隐式初始化,而其他类型的对象就必须显示初始化。new返回的也是一个const指针。
内存耗尽
当程序用光了所有可用内存,new就会失败,会抛出一个bad_alloc的异常,可以改变new的方式来阻止异常:
1 | //如果分配失败,new返回一个空指针 |
这种new为定位new,这种形式允许我们传递额外参数,nothow就是告诉它不能抛出异常。以上类型都在头文件new中。
释放动态内存
我们使用delete来释放内存:
1 | delete p; // p必须指向一个动态分配的对象或是一个空指针 |
但传递给delete的指针必须是指向动态分配的内存或空指针,其他行为是未定义的。
const对象的值不能被改变,但是本身可以销毁,同样delete指向它的指针。
动态对象的生存期直到被释放时为止
如果不使用智能指针,那么必须显示的释放它。
1 | // factory 返回一个指针,指向一个动态分配的对象 |
所以必须在use_factory中delete掉这个p,或者return出去让外部释放。
坚持使用智能指针,避免所有这些问题。
delete之后重置指针
delete指针之后,指针值就无效了,虽然指针已经无效,但有些仍保存着地址,为空悬指针:即指向一块曾经保存数据对象但现在已经无效的内存指针。
它和未初始化指针很像,解决办法是,在指针即将离开其作用域之前释放它所关联的内存,这样没有机会继续使用,也可以在delete之后给其赋值为nullptr。
shared_ptr和new结合使用
我们可以用new返回的指针来初始化智能指针:
1 | shared_ptr<double> p1; //shared_ ptr可以指向一个double |
接受参数的智能指针是explicit的,因此我们不能将一个内置指针隐式转换为智能指针,必须使用直接初始化形式:
1 | shared_ptr<int> p1 = new int (1024); // 错误:必须使用直接初始化形式 |
不可混用普通与智能指针
1 | int *x(new int (1024)) ; |
将临时的shared_ptr传递给函数,在调用结束后就会被销毁,则x变为空悬指针。
当将一个shared_ptr绑定到一个 普通指针时,我们就将内存的管理责任交给了这个shared_ptr.-旦这样做了 ,我们就不应该再使用内置指针来访问shared__ptr所指向的内存了。
也不要使用get初始化另一个智能指针或者为智能指针赋值
智能指针定义了名为get的函数,返回一个内置指针,指向智能指针管理的对象。此函数是为了这样一种情况二设计的:是为了不能使用智能指针的代码使用,但此指针不能delete。
1 | shared_ptr<int> p(new int(42)); //引用计数为1 |
其他shared_ptr操作
使用reset将一个新指针赋予它:
1 | p = new int(1024) ; //错误:不能将一个指针赋予shared_ ptr |
通常与unique一起使用,控制多个shared_ptr共享的对象,检查自己是当前对象仅有的用户,如果不是,在改变之前要做一次新的拷贝:
1 | if (!p.unique()) |
智能指针和异常
在函数中使用智能指针,即使函数发生了异常,局部对象也会被销毁,而如果使用new,则在delete之前出现异常不会自动释放。
智能指针指针和哑类
有一些为C和C++两种语言设计的类,通常要求用户显示的释放所使用的任何资源。我们可以使用管理动态内存类似的技术管理不具有良好定义的析构函数,例如:
1 | struct destination; //表示我们正在连接什么 |
如果connection没有析构函数,就会造成内存泄漏,可以使用shared_ptr保证connection被正确关闭。
使用自己的释放操作
首先定义一个函数来代替delete,这个删除器函数必须能够完成对shared_ptr保存的指针进行释放的操作。
1 | void end_connection (connection *p) { disconnect(*p); } |
当p被销毁时,他会使用end_connection来代替delste,从而确保链接关闭。
智能指针可以提供对动态分配的内存安全而又方便的管理,但这建立在正确使用的
前提下。为了正确使用智能指针,我们必须坚持一些基本规范:
- 不使用相同的内置指针值初始化(或reset)多个智能指针。
- 不delete get()返回的指针。
- 不使用get()初始化或reset另一个智能指针。
- 如果你使用get()返回的指针,记住当最后一个对应的智能指针销毁后,你的指针就变为无效了。
- 如果你使用智能指针管理的资源不是new分配的内存,记住传递给它一个删除器。
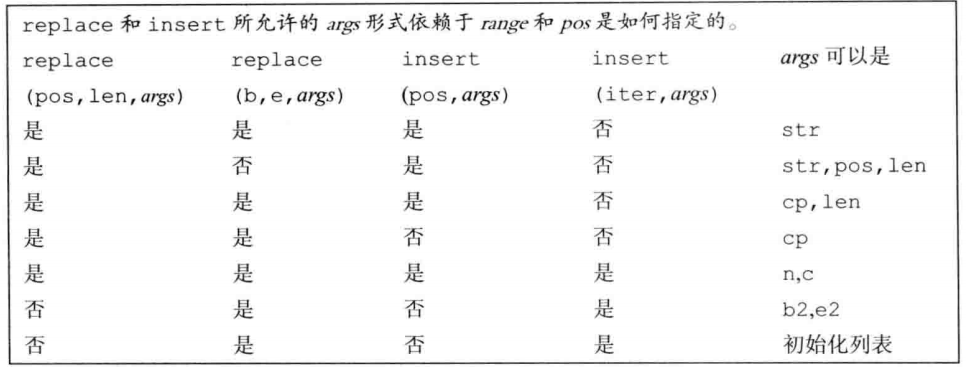
unique_ptr
一个unique_ptr“拥有”它所指的对象,且只能有一个unique_ptr指向给定对象,指针被销毁时对象也会被销毁。定义它时,没有make_shared类似的函数,需要绑定一个new返回的指针。
1 | unique_ ptr <double> p1; //可以指向一个double的unique_ ptr |
且不支持拷贝或赋值操作
但可以通过调用release或reset将指针转移所有权:
1 | //将所有权从p1 (指向string Stegosaurus)转移给p2 |
release成员返回unique_ptr当前保存的指针并置空,并且切断了它和原指针的联系,如果不移交给智能指针,一定要delete。
reset成员接受可选指针,然后重新指向给定指针。
函数中的unique_ptr
我们可以拷贝或赋值一个精要呗销毁的unique_ptr,如函数返回它。
1 | unique_ptr<int> clone(int p) { |
这是一种特殊的拷贝,将在之后介绍它。
传递删除器
与shared_ptr类似,可以重载删除器,一样需要提供删除器类型,在创建或reset时提供指定类型的可调用的删除器。
1 | // P指向一个类型为objT的对象,并使用一个类型为delT的对象释放objT对象 |
用unique_ptr代替shared_ptr:
1 | void f(destination &d /*其他需要的参数*/) |
在本例中我们使用了decltype来指明函数指针类型。由于decltype (end_ connection) 返回一个函数类型,所以我们必须添加一个*来指出我们正在使用该类型的一个指针。
weak_ptr
它是一种不控制所指向对象生存期的智能指针,它指向由一个shared(后面都简写)管理的对象将weak绑定到shared不会增加shared的引用计数,计数归0,即使有weak对象也会被释放。weak名字意为这种指针“弱”共享对象。

创建weak时需要用shared初始化它:
1 | auto P = make_shared<int> (42) ; |
因为weak若共享特性,它指向的对象可能不存在,所以在访问时必须调用lock判断,它返回一个指向共享对象的shared:
1 | if (shared_ptr<int> np = wp.lock()) { //如果np不为空则条件成立 |
核查指针类
如果将StrBolb类定义一个伴随指针,保存一个weak_ptr,指向StrBolob的data成员,使用weak不会影响StrBlob指向vector的生存期,但可以阻止用户访问不存在的vector。
1 | //对于访问一个不存在元素的尝试,StrBlobPtr抛出一个异常 |
此类需要注意不能将StrBlobPtr绑定到一个const StrBlob对象是因为构造函数只接受非const对象的引用
check函数也与之前不同需要检查指向的vector是否还存在:
1 | std::shared_ptr<std: :vector<std: :string>> |
指针操作
现在我们将定义deref和incr的函数来解引用和递增StrBlobPtr
1 | std::string& StrBlobPtr::deref() const |
动态数组
如果需要可变数量的对象时,可以使用在StraBlob中采取的方法。
new和数组
定义:
1 | //调用get_size确定分配多少个int |
最后的代码等于int *P new int[42];
在分配后得到元素类型的指针,所以不能使用begin或end,不可以用范围for来处理动态数组的元素
要记住我们所说的动态数组并不是数组类型,这是很重要的。
初始化动态分配的数组
可以使用默认初始化或者值初始化(跟一对空括号)
1 | int *pia = new int[10]; // 10 个未初始化的int |
还可以提供初始化器:
1 | //10个int分别用列表中对应的初始化器初始化 |
与内置初始化一样,初始化器会初始化开始部分的元素,剩余执行值初始化。
我们不可以在括号内给出初始化器,且不能用auto分配数组。
动态分配空数组
可以用任意表达式唉确定分配相对数目
1 | size_t n = get_size(); //get_size 返回需要的元素的数目 |
cp可以就像尾后迭代器一样使用
释放动态数组
1 | delete P; // p必须指向一个动态分配的对象或为空 |
释放元素是按逆序销毁,且方括号是必须的
1 | typedef int arrT[42] ; // arrT是42个int的数组的类型别名 |
智能指针和动态数组
标准库提供了一个可以管理new分配的数组的unique版本。但必须在对象后跟一对空方括号
1 | //up指向一个包含10个未初始化int的数组 |
当一个unique指向一个数组时,我们可以使用下标运算来访问数组中的元素:
1 | for (size_t i = 0;i != 10; ++i) |

与unique不同的是shared不支持管理动态数组。如果希望使用shared管理动态数组需要自定义删除器:
1 | //为了使用shared_ptr,必须提供一个删除器 |
这里直接传递一个lambda表达式作为删除器。如果不提供删除器,则后果与delete不加[]一样。此外他也不支持下标运算:
1 | // shared_ ptr未定义下标运算符,并且不支持指针的算术运算 |
所以只能使用get获取内置指针来访问数组元素
allocator类
new有一些缺陷:因为它将内存分配与对象构造组合在一起,所以会导致不必要的浪费:
1 | string *const P = new string[n]; // 构造n个空string |
这里创建了n个string,但可能并不需要这么多,所以造成了浪费。
新的方法allocalltor
它定义在头文件memory中,帮助我们将内存分配和对象构造分开。分配时需要给出类型:
1 | allocator<string> alloc; //可以分配string的allocator对象 |

分配未构造的内存
使用alloc.construct构造对象,额外的参数用于调用对象的构造函数。
1 | auto q = p; //q指向最后构造的元素之后的位置 |
在没有构造的情况下访问内存试错误的:
1 | cout << *p <<endl; //正确:使用string的输出运算符 |
当用完对象后,必须对每个构造元素调用destroy来销毁它们。接受一个指针对指向对象执行析构:
1 | while (q != p) |
销毁元素后可以重新使用内存,也可以归还系统
1 | alloc.deallocate(p, n) ; |
需要注意的是,第二个大小参数必须与调用allocate时一样。
拷贝和填充未初始化内存
1 | //分配比vi中元素所占用空间大一倍的动态内存 |
使用标准库:文本查询程序
此部分将单独作为一章。