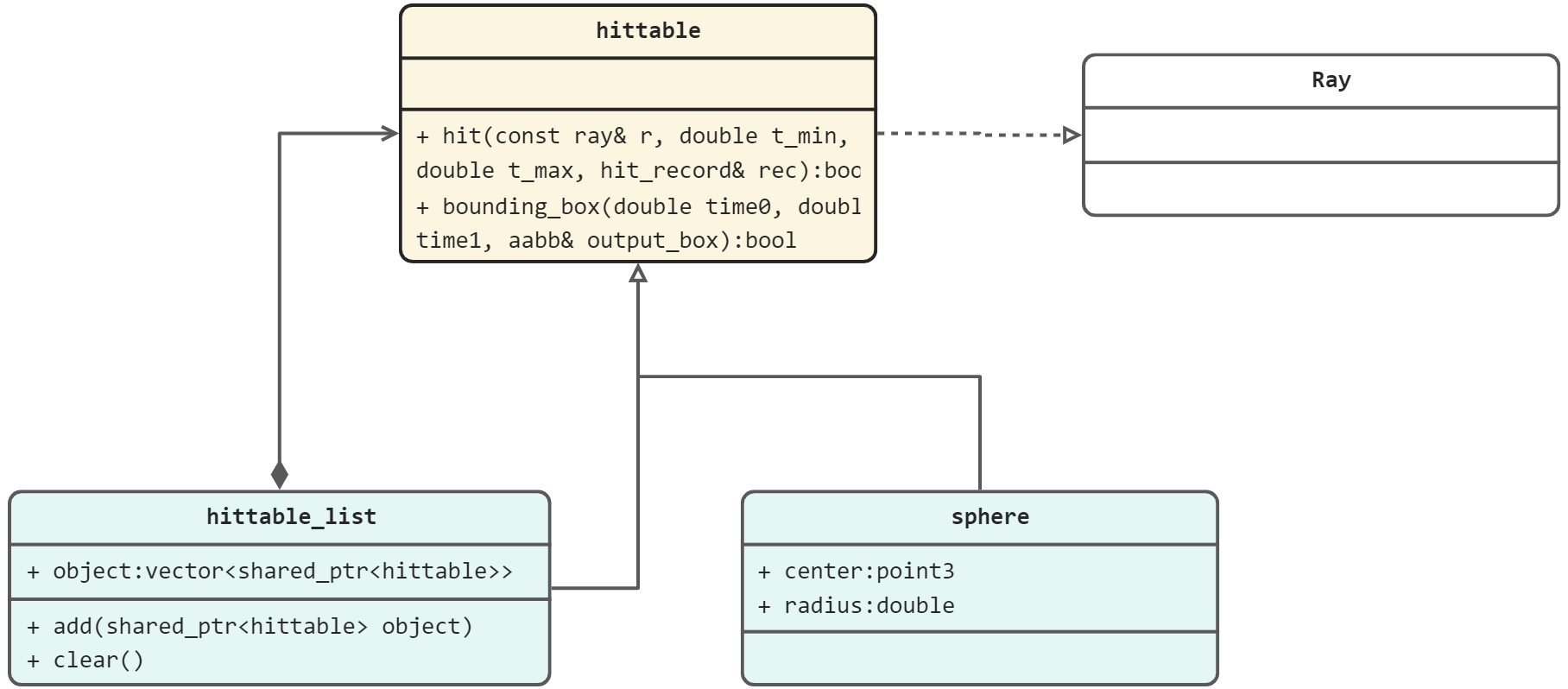
//读取指定文件中的 Json数据 反序列化 public T LoadData<T>(string fileName, JsonType type = JsonType.LitJson) where T : new() { //确定从哪个路径读取 //首先先判断 默认数据文件夹中是否有我们想要的数据 如果有 就从中获取 string path = Application.streamingAssetsPath + "/" + fileName + ".json"; //先判断 是否存在这个文件 //如果不存在默认文件 就从 读写文件夹中去寻找 if(!File.Exists(path)) path = Application.persistentDataPath + "/" + fileName + ".json"; //如果读写文件夹中都还没有 那就返回一个默认对象 if (!File.Exists(path)) return new T();
//进行反序列化 string jsonStr = File.ReadAllText(path); //数据对象 T data = default(T); switch (type) { case JsonType.JsonUtlity: data = JsonUtility.FromJson<T>(jsonStr); break; case JsonType.LitJson: data = JsonMapper.ToObject<T>(jsonStr); break; }
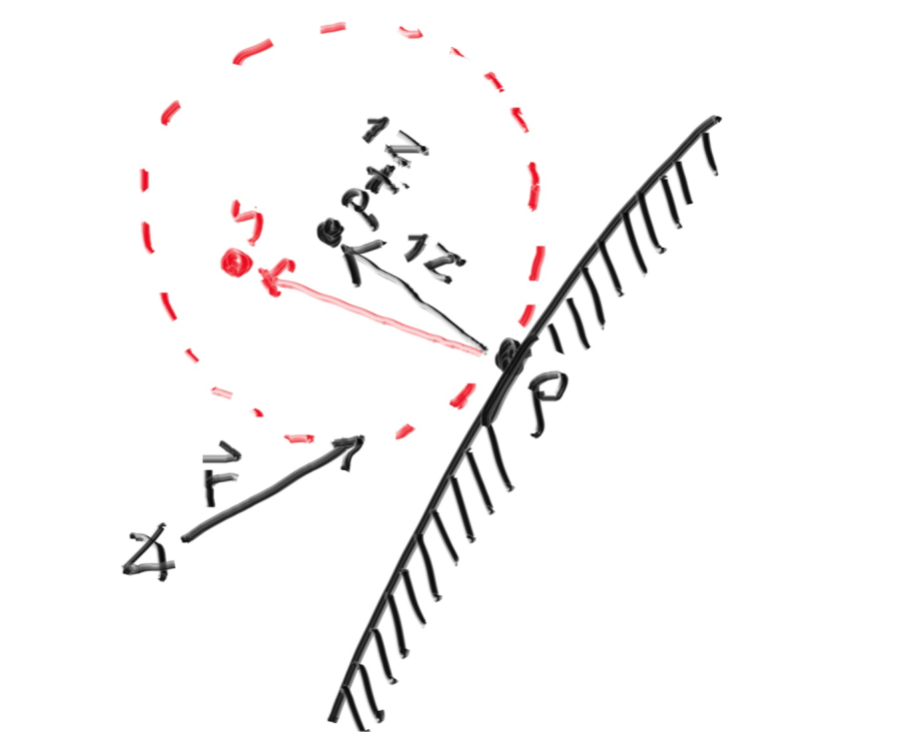
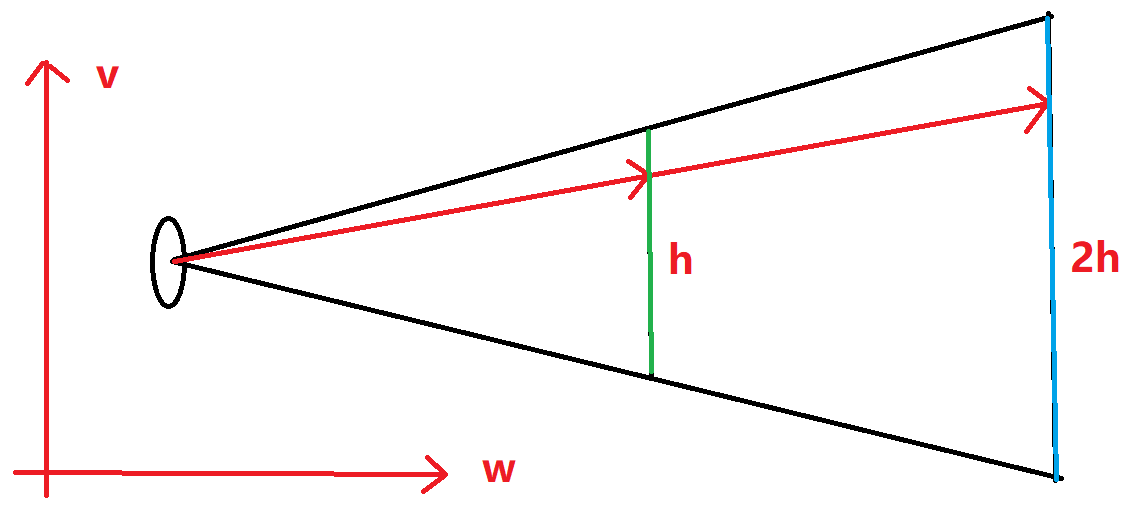
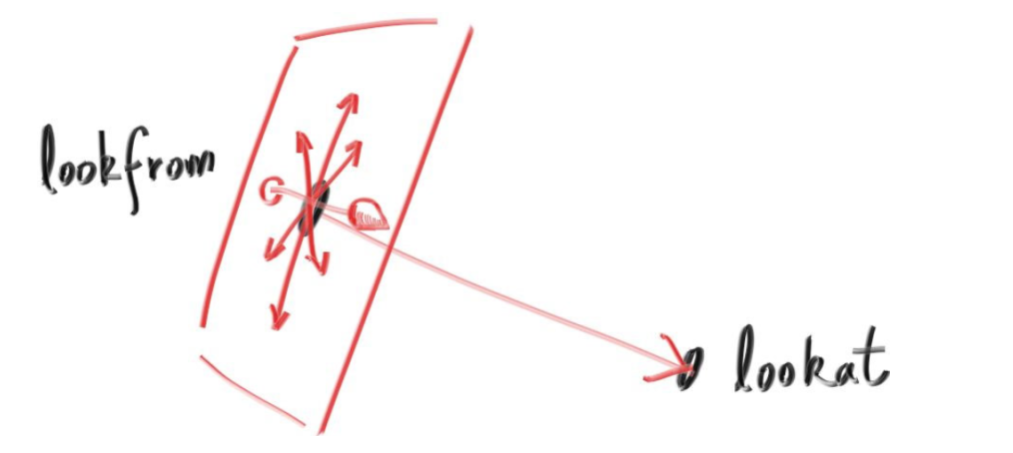
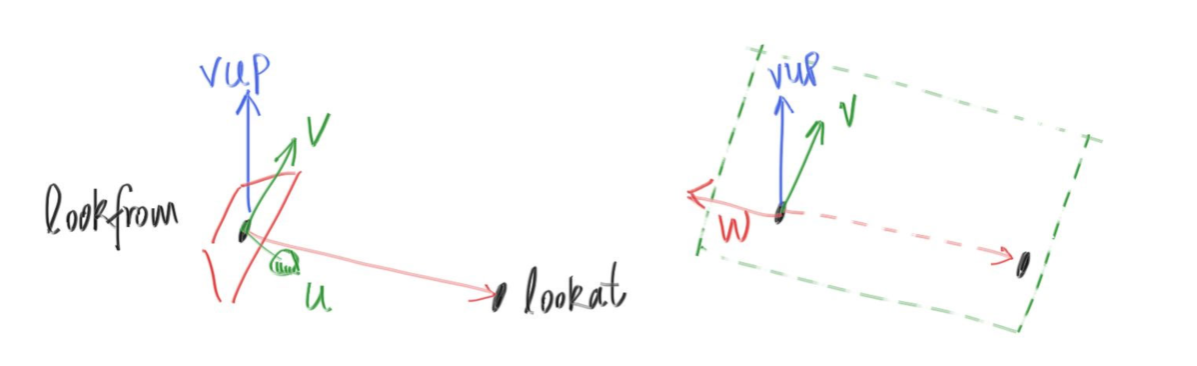
classcamera { public: camera( // 相机位置。 point3 lookfrom, // 相机看向的目标点。 point3 lookat, // 相机正上方方向向量(通常为(0,1,0))。 vec3 vup, // 视场大小。 double vfov, // 长宽比。 double aspect_ratio ) { auto theta = degrees_to_radians(vfov); auto h = tan(theta/2); auto viewport_height = 2.0 * h; auto viewport_width = aspect_ratio * viewport_height;
// w向量是从lookat指向lookfrom的向量。 auto w = unit_vector(lookfrom - lookat); // u向量与vup和w都垂直,我们可以直接叉乘得到它。 // 叉乘注意两个变量的前后顺序,注意叉乘结果向量的方向满足右手定则。 auto u = unit_vector(cross(vup, w)); // v向量与w及u向量都垂直,叉乘得到。 auto v = cross(w, u);
voidwrite_color(std::ostream &out, color pixel_color, int samples_per_pixel){ auto r = pixel_color.x(); auto g = pixel_color.y(); auto b = pixel_color.z();
//Gamma矫正(Gamma = 2.0)。 auto scale = 1.0 / samples_per_pixel; r = sqrt(scale * r); g = sqrt(scale * g); b = sqrt(scale * b);
voidwrite_color(std::ostream &out, color pixel_color, int samples_per_pixel){ auto r = pixel_color.x(); auto g = pixel_color.y(); auto b = pixel_color.z();
// 除以采样次数 auto scale = 1.0 / samples_per_pixel; r *= scale; g *= scale; b *= scale;


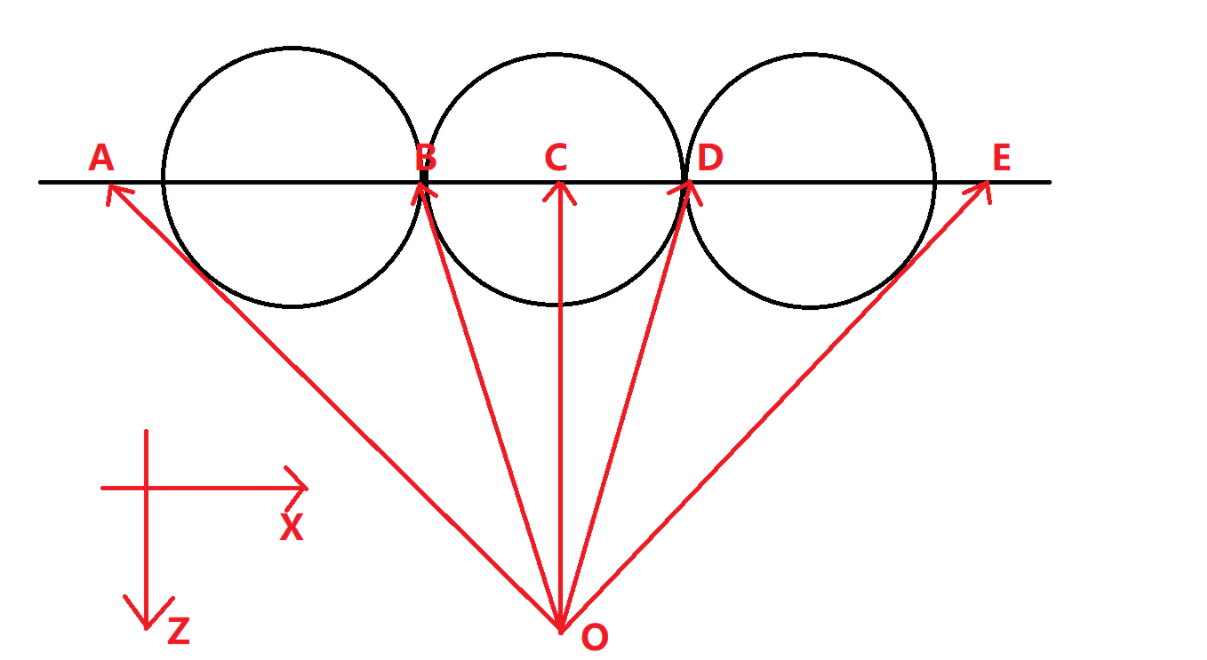
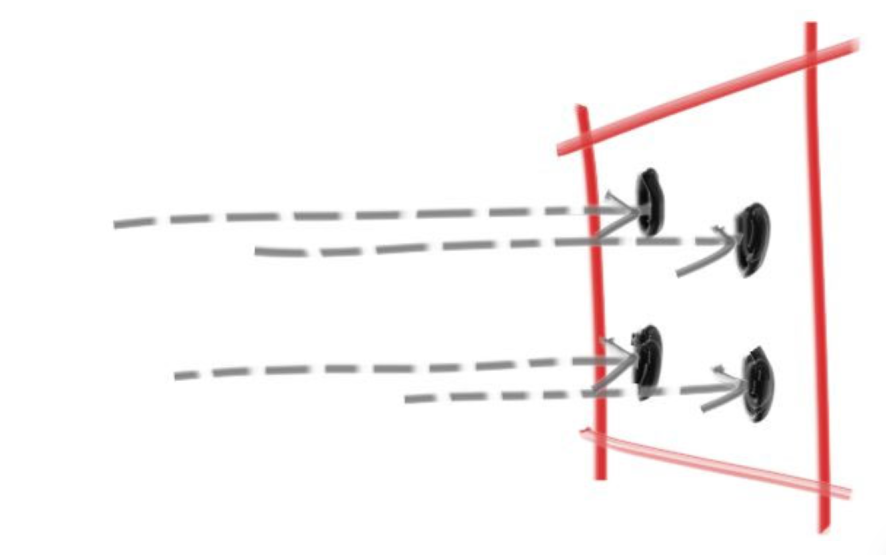
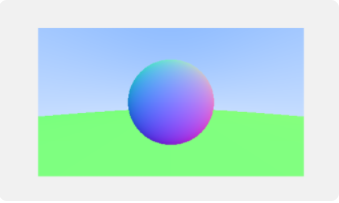
 如图所示,把虚拟视口缩小,这样图中的三个球在最终显示的图片上来看就不会有非常明显的长度不一的问题了。因为视口变小,视口中的像素数量不变,所以每个像素在三维空间中的大小也变小了,所以图片的最终质量并不会有任何改变。
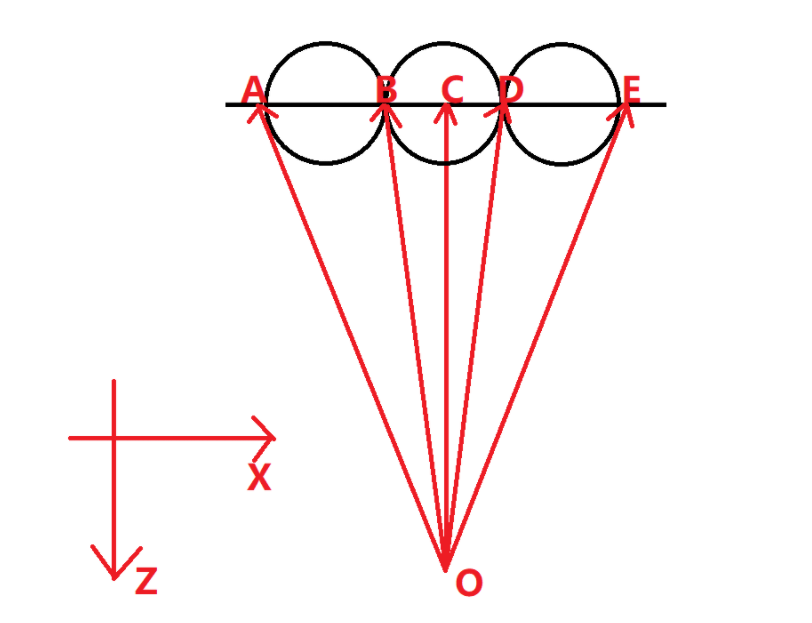
如图所示,把虚拟视口缩小,这样图中的三个球在最终显示的图片上来看就不会有非常明显的长度不一的问题了。因为视口变小,视口中的像素数量不变,所以每个像素在三维空间中的大小也变小了,所以图片的最终质量并不会有任何改变。


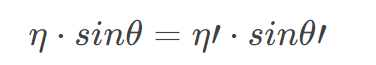
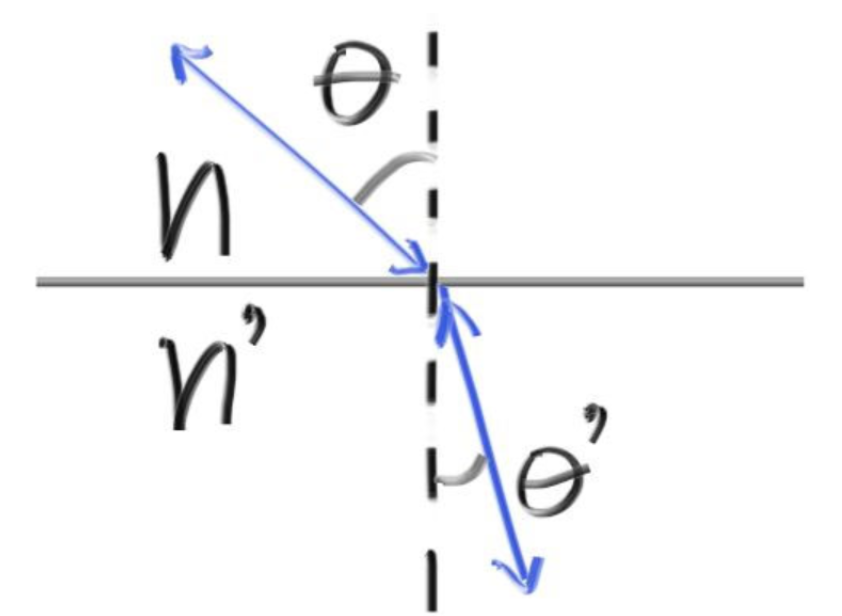









 2.夹角的余弦值cosθ。
2.夹角的余弦值cosθ。 去代替公式中的
去代替公式中的 接近1,第二项接近0,光线极度倾向于反射,罕有折射。
接近1,第二项接近0,光线极度倾向于反射,罕有折射。


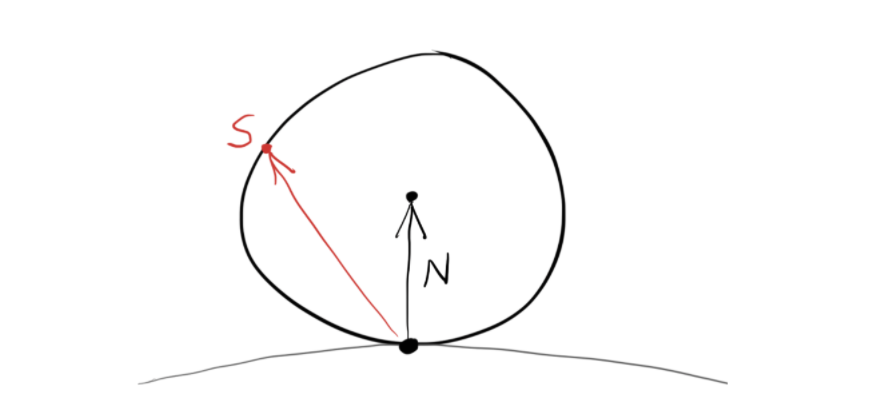
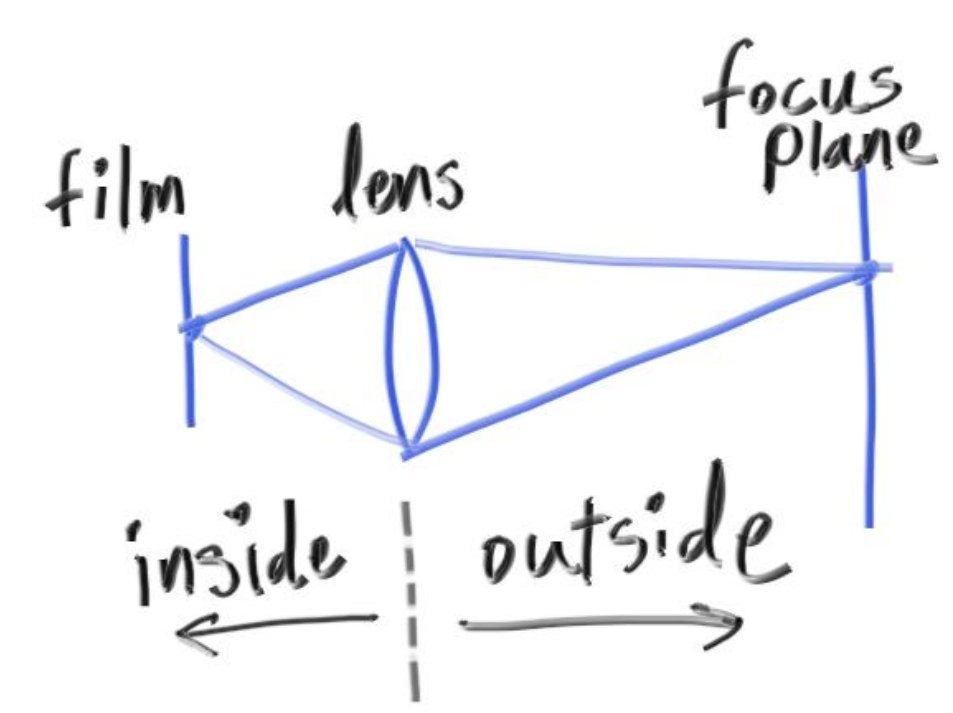
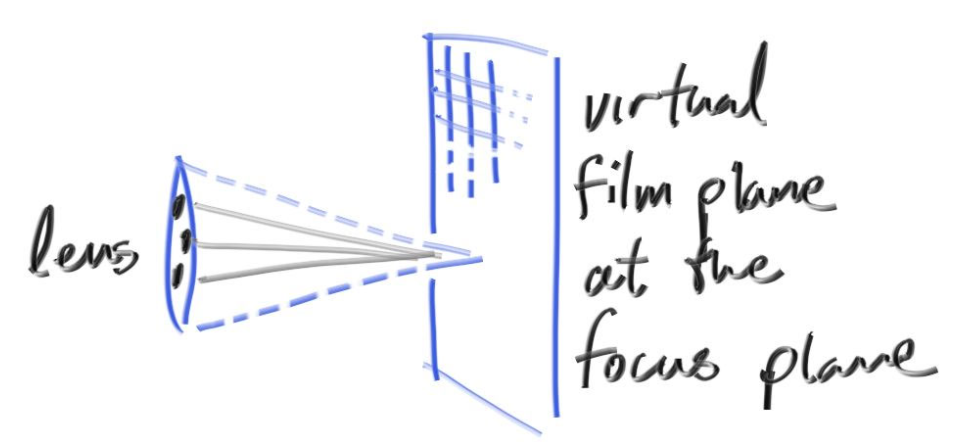
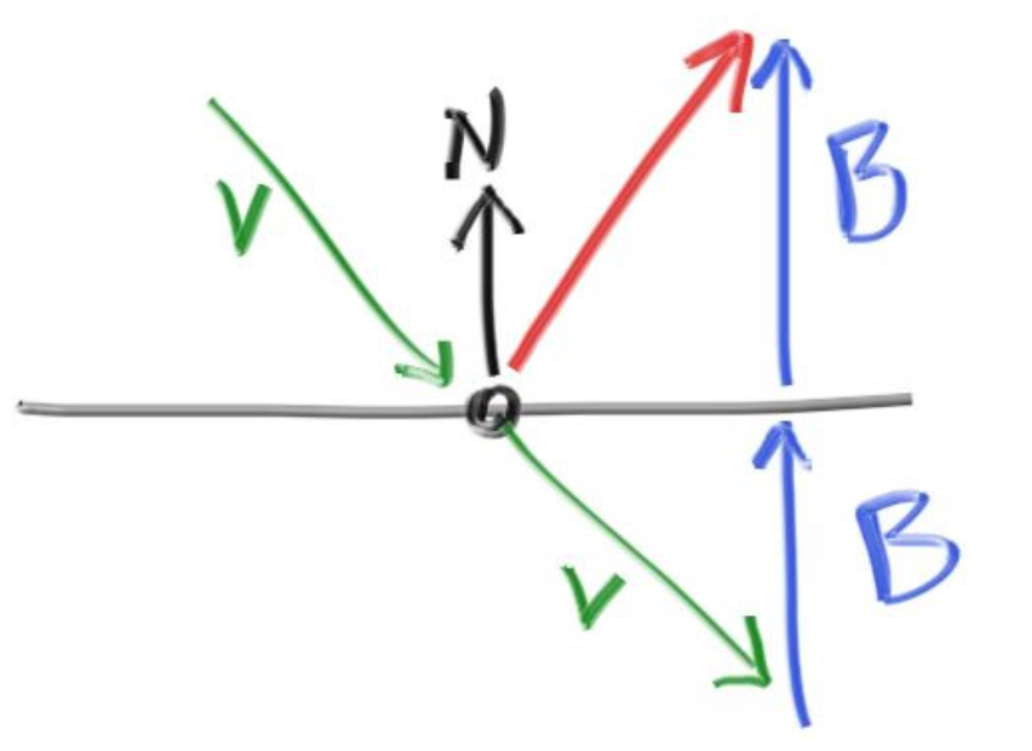 如图是一个平面,光线从上方射到平面上,法线方向朝上,红色的向量即是我们要求的向量。我们可以把入射向量的起点放到碰撞点,这样不难看出向量之间的关系:V+ 2B 即是反射光线方向。B可以看作是V在N上的投影的逆向量,又N在我们的设计中是单位向量,我们可以在vec3.h中加入如下类外函数:
如图是一个平面,光线从上方射到平面上,法线方向朝上,红色的向量即是我们要求的向量。我们可以把入射向量的起点放到碰撞点,这样不难看出向量之间的关系:V+ 2B 即是反射光线方向。B可以看作是V在N上的投影的逆向量,又N在我们的设计中是单位向量,我们可以在vec3.h中加入如下类外函数:




 。
。